* 참고 교재 : 혼자 공부하는 데이터 분석 (한빛미디어)
* 작성일 : 2023년 07월 23일
목표
판다스에서 데이터프레임의 특정 행(row)과 열(column)을 삭제하기
데이터는 도서관 정보나루에서 받아온 서울특별시 교육청 남산 도서관 장서 대출 목록 2023년 6월 (CSV) 파일을 이용했습니다. 아래 사이트에서 다운받을 수 있습니다.
도서관 정보나루
전국 서울 부산 대구 인천 광주 대전 울산 세종 경기 강원 충북 충남 전북 전남 경북 경남 제주 전체 영유아(0~5) 유아(6~7) 초등(8~13) 청소년(14~19) 20대 30대 40대 50대 60대 이상 전체 영유아(남) 영유
www.data4library.kr
데이터는 아래와 같이 작성되어 있습니다.
가장 마지막에 콤마(,)가 포함되어 있는 것이 특징(?)이라면 특징입니다.

먼저 데이터 프레임으로 한 번 출력해보겠습니다.
1 2 3 4 5 6 | import pandas as pd # 파일을 한번에 읽기 위해 low_memory 를 False 로 설정 df = pd.read_csv('서울특별시교육청남산도서관 장서 대출목록 (2023년 06월).csv', encoding='EUC-KR', low_memory=False) df.head() | cs |
마지막 콤마가 거슬렸는데, 데이터 프레임이 한 개의 열을 더 만들어버렸습니다.

열 Column 삭제
먼저 불필요한 열(column)을 없애보겠습니다.
1 2 | ns_book = df.loc[:, '번호':'등록일자'] ns_book.head() | cs |

데이터 프레임의 columns 속성을 이용하면 아래와 같이 인덱스 배열을 뽑아낼 수 있습니다

이 배열을 이용해서 특정 열을 삭제하는 것도 가능합니다.
df.columns != '열이름' 을 이용하면 아래와 같은 인덱스들의 boolean array 를 구할 수 있습니다.
이값을 loc 를 통해 넘겨주면 False 로 설정된 Columns 인덱스만 제외시킬 수 있습니다. 예로 확인하시죠.
1 2 3 4 5 6 7 8 | # 원소별 비교를 이용해서 마지막 열인 'Unnamed: 13' 을 제거하는 배열을 만들기 # Numpy Array 라고 합니다! df.columns != 'Unnamed: 13' # 이렇게 만들어진 배열을 loc 메서드에 전달하면 True 인 열만 출력하게 됩니다. selected_columns = df.columns != 'Unnamed: 13' ns_book = df.loc[:, selected_columns] ns_book.head() | cs |
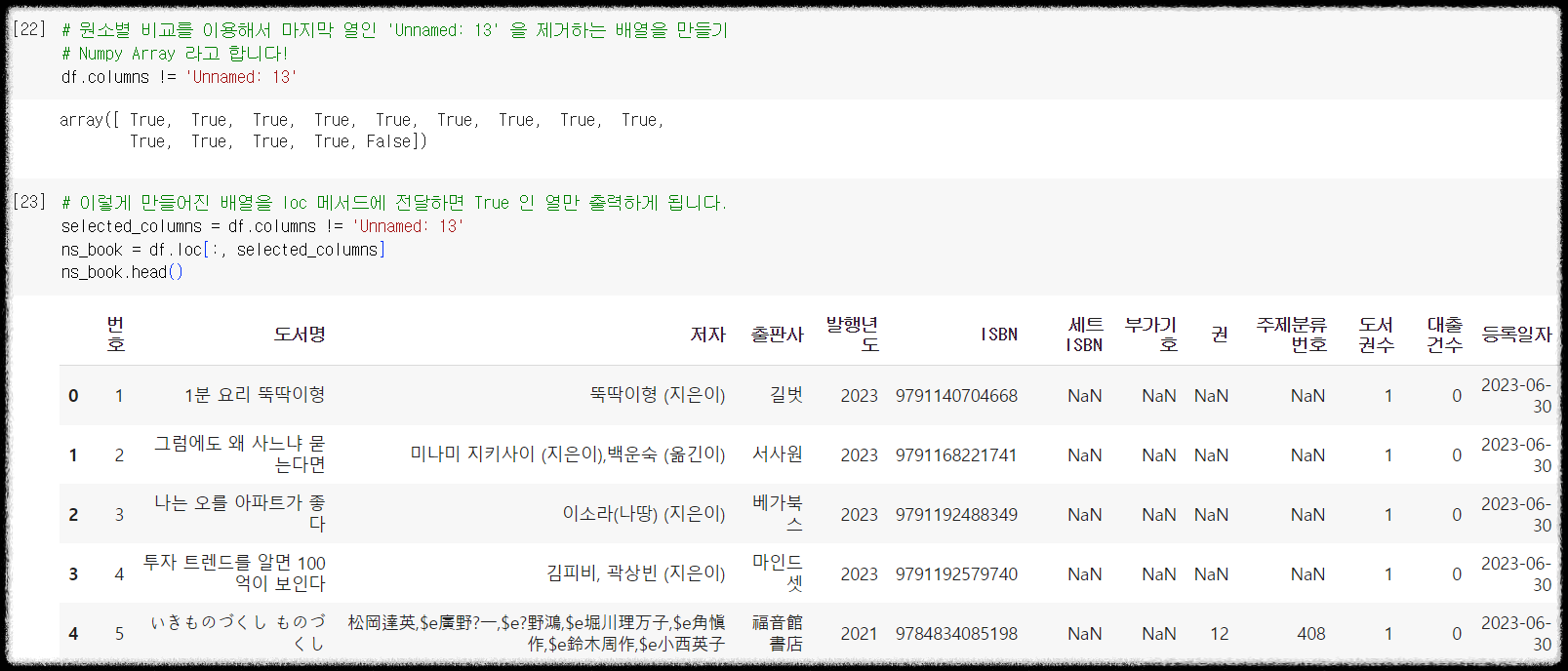
판다스는 drop 이라는 메서드를 지원합니다.
loc 를 사용하지 않고 drop 을 이용해서 열을 지울 수도 있습니다.
1 2 3 4 5 6 7 | # 마지막 행인 Unnamed:13 을 삭제합니다 ns_book = df.drop('Unnamed: 13', axis=1) ns_book.head() # 리스트 형식으로 넣어서 여러 열을 동시에 삭제할 수도 있습니다. ns_book = df.drop(['부가기호', '세트 ISBN', 'Unnamed: 13'], axis=1) ns_book.head() | cs |
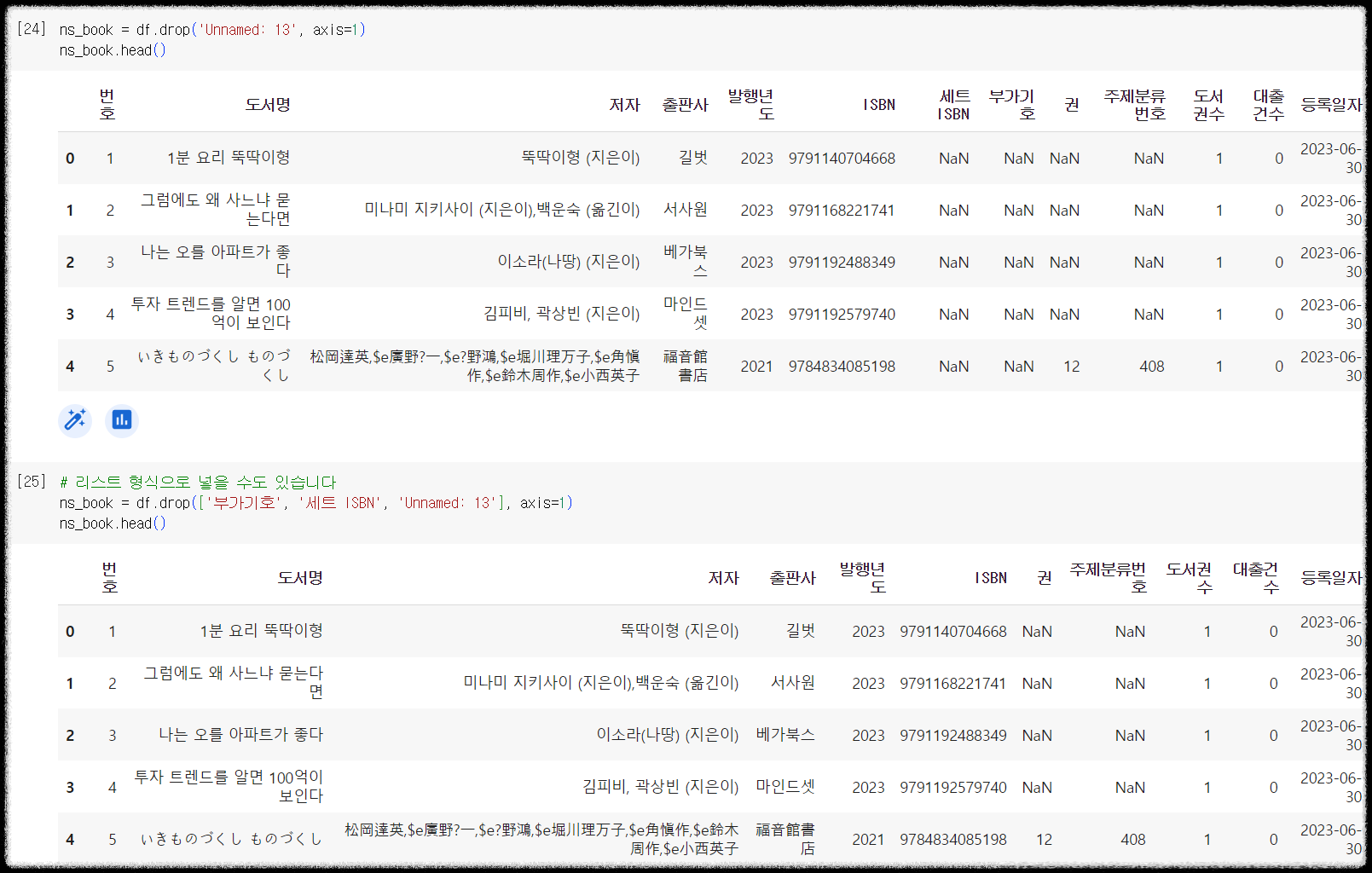
inplace 속성을 True 로 설정해주면 위의 예처럼 데이터프레임을 다시 반환 받지 않고 데이터프레임을 즉시 수정할 수도 있습니다. 조금은 위험할 수 있겠죠?
1 2 3 | # inplace 를 이용하면 데이터프레임에 바로 drop 을 적용할 수 있습니다. ns_book.drop('주제분류번호', axis=1, inplace=True) ns_book.head() | cs |
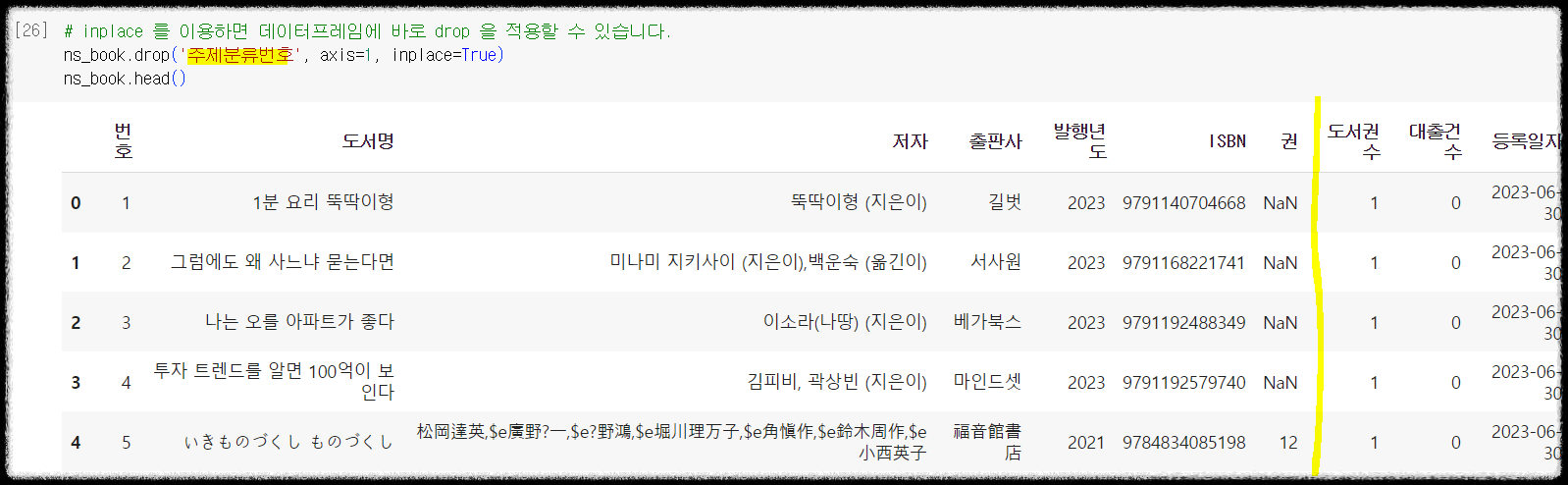
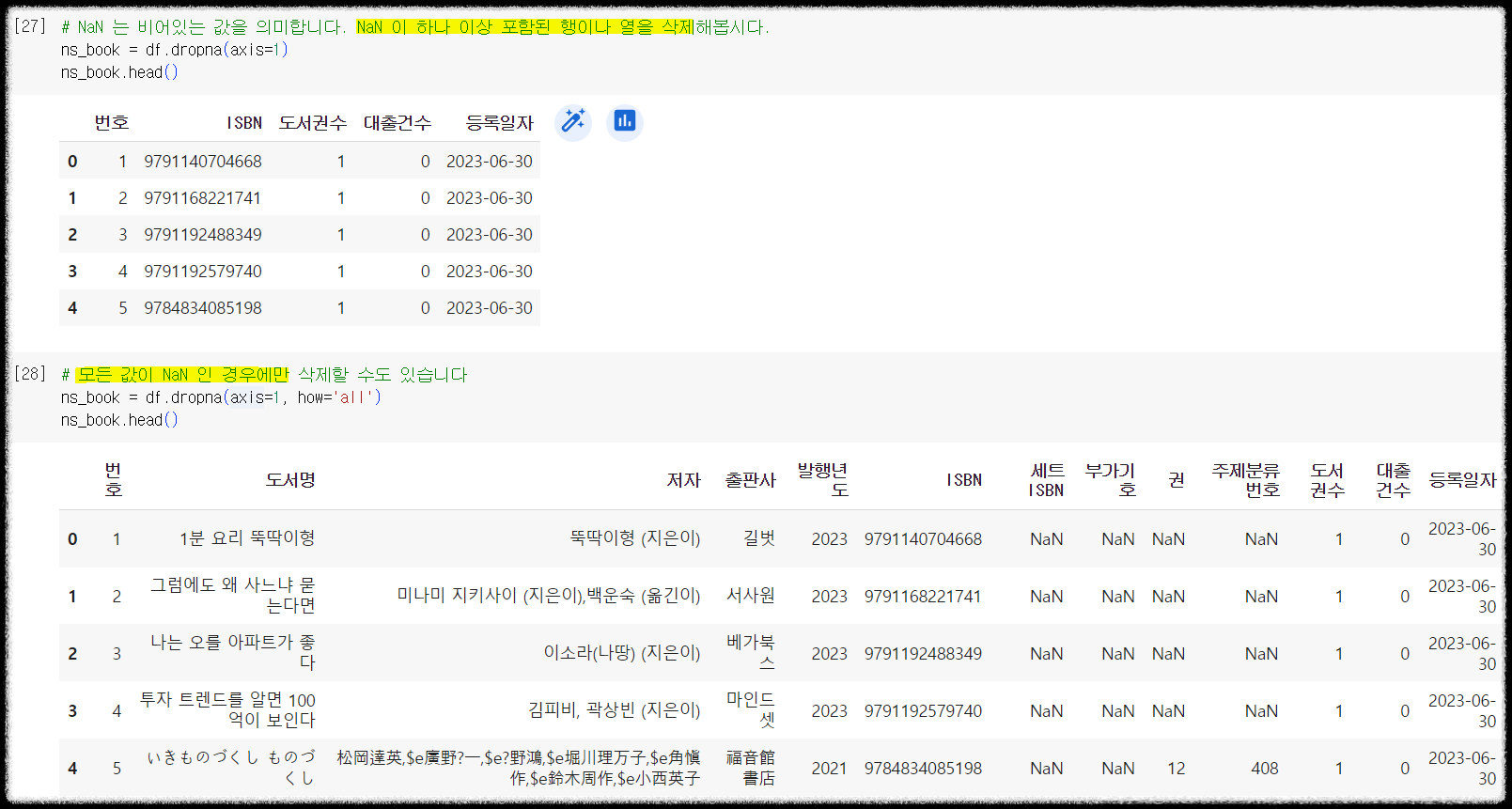
데이터가 많다보면 실제로 비어있는 곳도 많이 있을 수 있습니다. 위 예제들도 그런 곳이 많이 보이네요. NaN 으로 표시된 곳들이 데이터가 없는 곳입니다. 이 값을 제거하기 위해 판다스는 dropna 라는 함수를 제공하고 있습니다. dropna 를 이용하면 모든 값이 NaN 인 값을 제거하거나 하나라도 NaN 인 값이 있는 경우의 열을 삭제하는 것도 가능합니다.
1 2 3 4 5 6 7 | # NaN 는 비어있는 값을 의미합니다. NaN 이 하나 이상 포함된 행이나 열을 삭제해봅시다. ns_book = df.dropna(axis=1) ns_book.head() # 모든 값이 NaN 인 경우에만 삭제할 수도 있습니다 ns_book = df.dropna(axis=1, how='all') ns_book.head() | cs |
행 Row 삭제
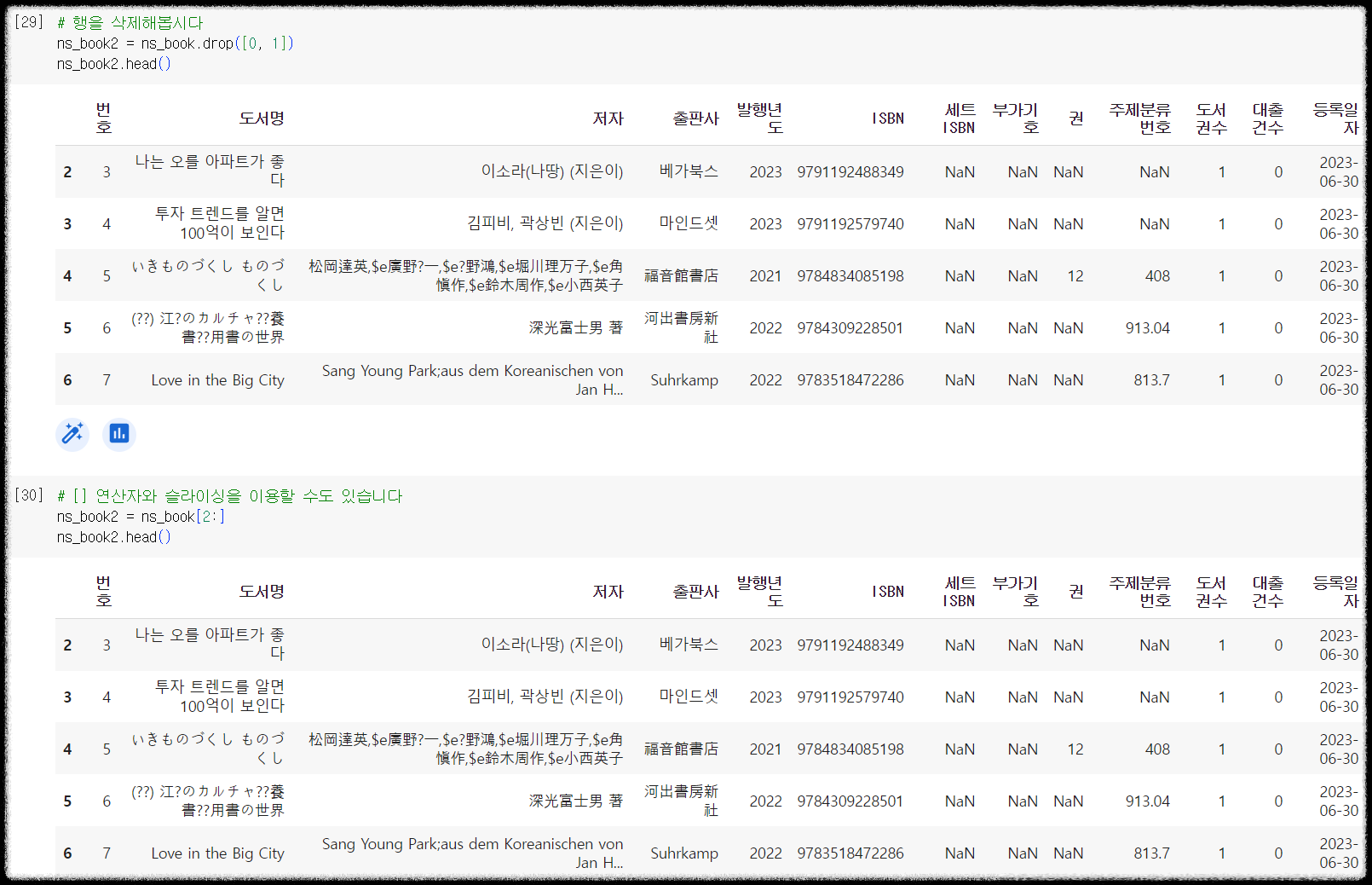
drop에 삭제할 행을 배열로 지정해서 넘겨주면 됩니다. 직관적이죠? 그리고 슬라이싱도 이용할 수 있습니다.
1 2 3 4 5 6 7 8 | # 0, 1 행을 삭제해봅시다 ns_book2 = ns_book.drop([0, 1]) ns_book2.head() # [] 연산자와 슬라이싱을 이용할 수도 있습니다 # 2행 이상만 남기기 ns_book2 = ns_book[2:] ns_book2.head() | cs |
특정 행만 남기고 나머지는 삭제해보겠습니다.
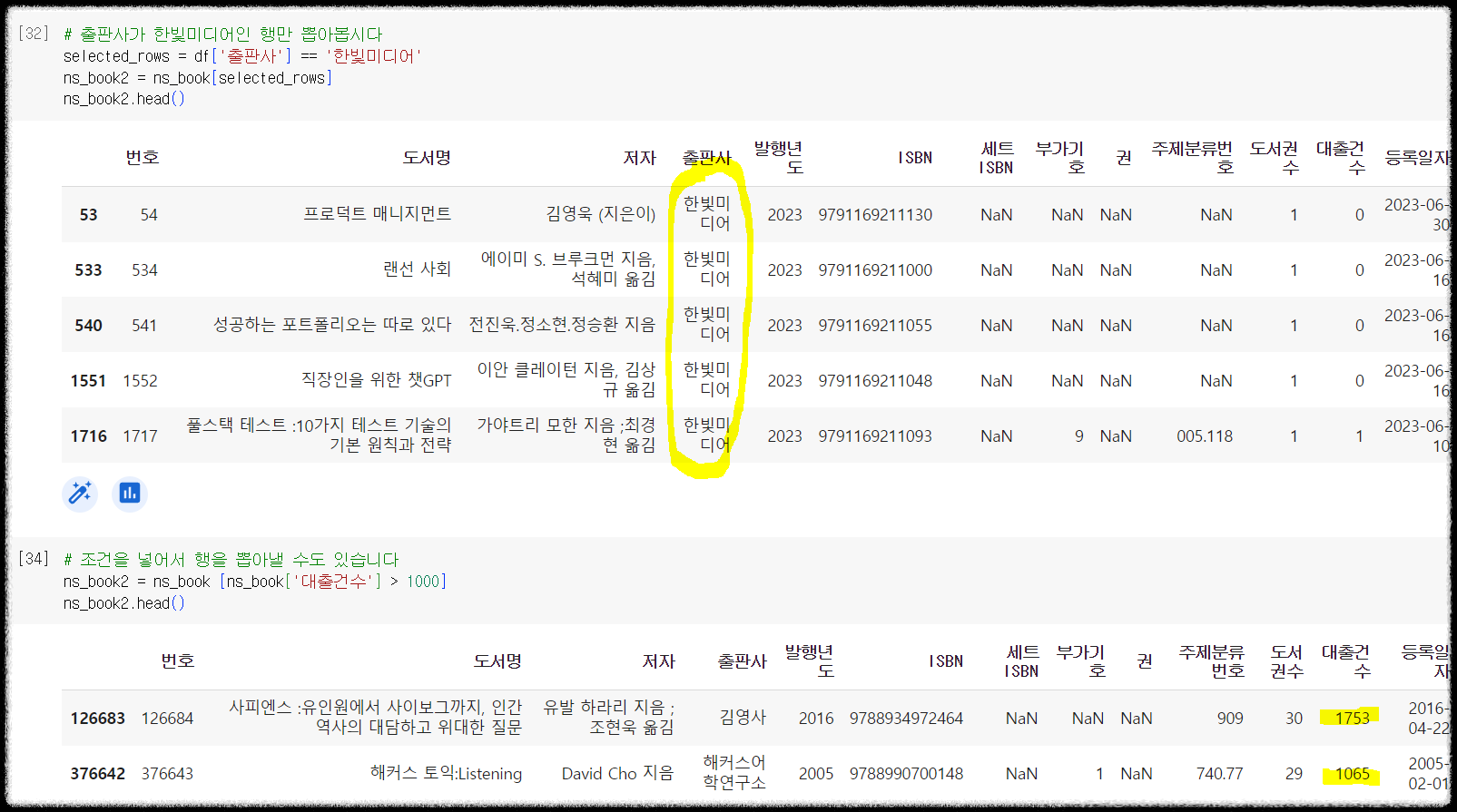
출판사가 한빛미디어인 경우와 대출건수가 1000건이 넘는 경우에만 남기는 예를 살펴보면 다음과 같습니다.
1 2 3 4 5 6 7 8 | # 출판사가 한빛미디어인 행만 뽑아봅시다 selected_rows = df['출판사'] == '한빛미디어' ns_book2 = ns_book[selected_rows] ns_book2.head() # 조건을 넣어서 행을 뽑아낼 수도 있습니다 ns_book2 = ns_book [ns_book['대출건수'] > 1000] ns_book2.head() | cs |
끝.
'개발 Dev > 데이터 분석' 카테고리의 다른 글
| [데이터분석/파이썬] requests와 Bueatiful Soup를 이용해서 웹 크롤링하기: yes24에서 책 페이지 수 가져오기 (1) | 2023.07.16 |
|---|---|
| [데이터분석/파이썬] 도서 정보 OpenAPI 사용하기 (도서관 정보나루) (0) | 2023.07.13 |
| [데이터분석/파이썬] XML 포맷 다루는 방법 (xml.etree.ElementTree, 판다스 read_xml) (0) | 2023.07.09 |
| [데이터분석/파이썬] json 포맷 다루는 방법 (json, pandas) (0) | 2023.07.09 |
| [데이터분석/파이썬] csv 파일을 Pandas 데이터프레임으로 읽기 / 데이터프레임을 csv 파일에 쓰기 (0) | 2023.07.09 |